Are you looking for an essay on ‘Data Processing’? Find paragraphs, long and short essays on ‘Data Processing’ especially written for school and college students.
Essay on Data Processing
Essay Contents:
- Essay on the Meaning of Data Processing
- Essay on the Concept of Data Processing
- Essay on the Techniques of Data Processing
- Essay on the Methods of Data Processing
- Essay on the Manipulation of Data Processing
- Essay on the Organisation of Data Processing
- Essay on Data and Information
1. Essay on the Meaning of Data Processing:
The term Data Processing includes all the activities undertaken to convert data to information and in our case, using computers. For example, when you go to buy a railway ticket, data processing involves getting information about the reservation requested and printing out the ticket, if available—the whole process of preparing your ticket being called a transaction.
In practice there can tie thousand types of transaction like, preparing a blood analysis report, tabulating examination results, preparing annual accounts, and so on. In all cases the output of data processing is the relevant information required, obtained by manipulating [processing] the input data.
Hence, data processing in general refers to manipulation of data, manually or by using machines, to produce meaningful information.
Here our concern is mainly with computerized data processing systems, in which, the data processing cycle involves input of data to the computer, manipulating or processing the data inside the computer using predefined instructions, and as a result, generating information, which is the output desired—I-P-O or Input-Process-Output.
Diagrammatically, the cycle is:
![]()
The computers have a special circuit which is capable of what is called Logical processing. What it simply does is compares two items or values, say A and B, and then takes one of the three different courses of actions depending on whether A is greater than B, or A is equal to B, or A is less than B. Obviously, we have to specify what is A and B, and what actions are to be taken under what logical conditions.
The computer can also state whether a certain fact is true or false, like, whether it is true or not that A is equal to B, if A = 10 and B = 20; the answer obviously would be No or False. Incidentally, the set of instructions in general is called Software.
2. Essay on the Concept of Data Processing:
The concept of data processing is not new. We do it daily in one way or other using personal skill. But the manual systems of data processing have their limitations—to process large number of data, we need lot of persons working for long hours and then with chances of mistakes, especially in jobs of monotonous nature, caused by fatigue, inattention, etc. With computers, we have two great advantages—speed and accuracy.
The computers can do millions of Calculations in seconds, which manually would take days to complete and secondly, once the correct data is given to the computer the information generated would be accurate—the computers are neither bored nor get tired.
Just compare the manual system of railway reservation with the computerized booking and you will realize the advantages of data processing using computers. But, there is a big difference. The computers just cannot think, it does not have the thing called intelligence or experience and so it is incapable of taking any decision.
That is why a computer, no matter how sophisticated it is, cannot solve a problem or carry out any type of data processing which a man cannot do.
A computer has to be told what to do with the data and how. As per one observation, if the IQ [Intelligent Quotient] of human beings is taken as 100, the relative IQ of a modern computer would be around 0.01, which is the estimated IQ of a dragon fly.
Incidentally, of all the inventions made so far the computer is the only one which multiplies our mental capability in some areas, all other being for improving our physical ability. For example, first we used our bare-hands to dig earth, then we used stone-pieces, then iron-rods, then excavators—each enabling us to do the same work with lesser and lesser physical efforts.
The computer, on the other hand supplements our processing speed, doing it day and night with diligence. That is the reason why in all spheres and especially in data processing, the computers are bound to be used extensively.
It should be pointed out that computers are not at all suitable in areas where the job is not of repetitive nature and which needs lot of thinking. Even, if you want to do a single multiplication involving two numbers, it would be useless to do it using a computer, as preparing the set of instructions and entering the data would take a longer time than what even a school student would take.
But if the job involves doing thousands or lakhs of multiplication, the computer would be really useful—it would do it much faster and always accurately; provided the program [the instructions] and the data are correct.
To summarise the relationship between the data and information, we can say, by comparing with industrial operation that, Data is the raw material which is processed to get the Information, which is the finished product.
Coming back to information, let us admit that we all need information, every-day and that is why we read newspapers, which inform us who won the cricket match, what are the prices of shares, when the next CA Examination is going to be held, and so on.
In computer systems of business organisations, information is created to satisfy various needs of the management, based on which decisions are made. Obviously, such information must be meaningful, precise, reliable, and on time. Sometimes we need past information to evaluate present performance, use present performance to forecast future course of actions.
In fact, in the annual reports of corporate bodies, it is compulsory to give the figures of the previous year along with those of current year. Often the statistics presented in economic areas are given as a comparison with figures of the corresponding figures of the past. The budgets that are prepared are heavily dependent on what is happening currently.
Information’s are often qualified with prefixes to indicate its relation to different areas of actions under different perspectives. For example, when we are talking of India versus foreign countries, we use the term national-information as against international-information.
Similarly, we have educational-information, commercial-information, cultural-information, and so on. It depends on how we want to look at the information. The prefix merely classifies or qualifies the type of information for better understanding.
3. Essay on the Techniques of Data Processing:
The computation of results, preparation of accounts, and other activities are being done for ages by people using pen, paper, and a ruler. But with time, as the number of data started becoming larger, the problem of data processing became unmanageable in the nineteenth century, especially in some cases like, the census of USA.
The census data collected there in 1880 was estimated to take nearly ten years to process manually, making the information lose its relevance and by that time the next census would have become due.
So, Herman Hollerith came into picture and he developed electro-mechanical data processing system using cards as input. The Hollerith System later came to be used extensively in commercial application and continued till 1960s.
These electro-mechanical processing devices, with paper cards containing input data in punched holes are generally come under EAM or Electrical Accounting Machines and the system is called Unit Recorder Method. It required a number of machines, for different operations such as, Punching, Verifying, Sorting, Collecting, Reproducing, and Tabulating.
There was practically no storage memory available, only UNIVAC 1004, introduced at late stage had some memory—making a hybrid machine which could process only one card at a time and thus acquired the name “Unit Record”.
Although these machines were a vast improvement over the previous data processing methods, it had limited operational facilities, needed volumes of specially made card which were created storage and associated problems.
These Hollerieth Machines were replaced by electronic computers, but mostly of large size called mainframe computers, about three decades ago.
The emergence and growth of the class of computers, variously called Personal Computers and Microcomputers in early 1980s, dramatically changed the technique of data processing and brought it to the stage which we are witnessing today —entering an age which is called EDP or Electronic Data Processing.
4. Essay on the Methods of Data Processing:
The common, basic unit of data processing in business is called transaction, which comprises entering of relevant input data, processing the data, and producing the information for each activity; obviously everything being done under the control of a computer armed with suitable set of instructions.
For example, entering the marks obtained by a student in an examination and preparing his mark-sheet in the required form is a transaction, recording sales or purchase of an item is a transaction, getting a railway ticket is also a transaction.
While processing data, hundreds and thousands of transactions of similar nature are processed in different ways and so data processing basically boils down to transaction processing. This kind of processing can generally be done in two ways, called, Batch Processing and Interactive Processing, also called On-line Processing.
In Batch Processing [or Sequential Processing], the data relating to all transactions of a particular type are first entered into the computer, after taking steps to ensure that these are accurate, by a process called data validation.
And, then all the data is processed one after another in one go in a batch or group to produce the final output—there is obviously a time gap between entering of an individual data and getting the final output, as the information would be available only when all the data have been processed.
This is generally followed for typical repetitive work like say payroll accounting, where the payroll of all the employees are prepared by continuous processing, after the necessary details of all the employees have been entered. Similarly, preparing the final result of an examination for all the students by processing all the input marks together is also called batch processing.
In the other type of processing, called On-line Processing, the processing of the input data is carried out immediately, when all the data relating to one particular transaction is entered into the computer. The classic example with which you are familiar is the buying of a ticket from the computerized railway reservation service.
The request of one person in the queue is processed completely before taking up the request of the second person. It is called on-line processing because; the operator is always in direct contact with the computer. The operator tells the computer what he wants through the keyboard and the computer replies through the display screen, hence, it is also called Interactive Processing.
5. Essay on the Manipulation of Data Processing:
The basic data processing operation carried out on the input data to add meaning to it are generally, Classifying, Sorting, Calculating, Collating, Merging, Searching, and Summarizing—whether we do it manually or using a computer.
Classifying is the process of organising data into groups of similar items—into small homogeneous groups based on some specific criterion. In a co-education class, the students’ data may be classified into, male and female students for analysing whether there is a difference in performance on account of sex.
Sorting is the process of arranging data in some predetermined logical order. For example, the names of the students may be arranged on alphabetical order from a to z, or the names arranged on, the basis of total marks obtained by each in some examination, in descending order, starting with the highest marks. The criterion used for sorting, like the marks in the second case, is called key.
Calculating is the process of carrying out arithmetic computation on numerical data from the simplest addition to the complex ones—although the computer basically carries out addition in various forms. This is the most common processing job carried out at the Arithmetic & Logic Unit (ALU); where logical computation involving Boolean Algebra is also carried out.
Collating is the process of comparing different sets of data and then carrying out some operation on the basis of the result of comparison. It is useful in the process of merging.
Merging is the process of creating a third set of data by combining two different sets of data having a common field [the smallest unit of data in a database file system], sorted in the same logical sequence on some criterion and then combining these two sets after collating.
Searching is the process of locating a particular data item from a set of data items. It is required to confirm absence or existence of a particular value. The search operation fails if the item is not found. A number, of searching procedures, generally called algorithms, are available, binary search being the most popular one.
Summarizing is the process of creating a few concise data items out of a mass of data. For example, the average marks computed is a summarisation of the individual marks of students in a particular examination.
Input of Data:
Before feeding into the machine, the input data need to be captured or recorded in a machine usable and readable form for processing by computer. For example, the computers in 1960s mostly used 80 or 96 column paper cards as input or source documents.
In such cases recording of input data involved punching rectangular holes in the cards using alphanumeric [alphabets and numerical together] codes representing characters. In modern computers, the recording of input data is mostly through the keyboard entries; though other input devices are also in use.
Technically, Recording means transfer of data into some computer readable forms or documents. Obviously, before inputting data, these must be collected from various internal and external sources, as the case may be. Collection means gathering relevant and necessary data for generating the particular information from a mass of data which are available in abundance in any business organisation or elsewhere.
In a college, for processing examination results of students, the marks given by different examiners and nothing else need to be collected to prepare the basic data, which is entered into the computer by using the keyboard, which is quite similar to a typewriter keyboard with some added facilities and additional keys.
Output of Data:
The activities coming under output operation are Displaying, Printing, Storing, Retrieving, and Communicating. Displaying is the process of showing the outcome of a processing operation on the video screen called Video Display. Unit [VDU], whereas, Printing is doing the same thing by typing out on paper using a printer—called hard copy.
Storing is the process of keeping data in a physical storage medium like tapes or disks for future use. The data is transferred from primary to secondary storage—the former being the memory of the computer.
Retrieving is the reverse process of storing. This involves getting a data or a particular set of data from a mass of data stored on a physical medium. It does not destroy the data stored.
Communicating is transferring data from one source to another. It may involve different geographical regions where networks are used for transferring data. Displaying and printing are also part of the process of communicating.
6. Essay on the Organisation of Data Processing:
It is rare that some data are entered into the computer system, processed to generate information and then thrown away, like we do when using electronic calculators. In practice, there is a definite need to store data in a systematic manner for future use and this has been the area which has received most aggressive attention of computer experts.
In the process, new systems have come into existence, new terminologies coined; some time referring to the same idea. Generally the terms in common use, relating to data base systems, has two origins—one is IBM’s Data Language I [DL/I] and the other is CODASYL’s [Conference on Data System Language] Data Description Language.
Although bits or bytes are the smallest unit of recording data physically, as per IBM’s DL/I, a Field is the smallest named unit of data, which is given a definite name, has a specified size and type.
Expressed in simpler language, as we are dealing with data bases in general not restricting to any specific data description language, a Field is the smallest unit of data within each record, containing specific data or information relating to that record and having a distinct name. A number of fields built up a Record.
For example, in our personal address books we keep data/information of our friends and acquaintances. What do we note down? The name (first-name, middle-name, last-name), house number with street/road, city/town, state, pin code, telephone number, if any, etc.
Now, as per data base terminology, the detail about each person will be recorded in different fields like one field for name, another field for house number with street, etc. In fact it is our choice how we will treat the name and address in terms of fields.
For example, we can break the name and use three fields for first-name, middle-name, and last-name—it depends on what we are going to do with our data. In the address book, details of each of our friends and acquaintances will have to be filled up in the relevant fields. How do we accommodate them? We have one record for each friend and acquaintances.
We keep all the records in one address book to readily access it—similarly with computers, we store all the records together in a data file with a distinct name to it—we may call it Address File. So, a record contains all the data about a single item, like that for our friends and acquaintances, in the data base file.
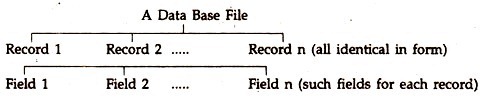
All fields in a data file are identical in form, with each field of each record containing different data. For example, the Field 1 of Record 1 may contain Ashok, that of Record 2 may contain Kapil, and so on. A sample of a data base file is shown in Figure 1.1 with a few items.

If you look at the logical view of the file [the way the user looks at the data] you will notice that it is a simple two-dimensional table, with fields as the columns and the records as rows. Such a two-dimensional table [also an array] is sometimes called a flat file. The table of this type is also referred to as a relation. A set of data items can be grouped in different ways to form different records for different purposes.
The basic objective of data file is to provide for a systematic storage of data, which can be easily stored, quickly retrieved and easily processed to generate the desired information. In a data file, to summarise, broadly speaking, fields constitute a record, records constitute a data file, and data files constitute a data base. Under the CODASYL terminology, a field is called a “data-name”.
Data Files:
Data base files can be broadly classified into two categories depending on the permanency of data stored in relation to time—called Master File and Transaction File. The Master File is a file of almost permanent nature which contains all the data required for a given application.
On the other hand, Transaction Files are created periodically to hold data relating to current transactions like sales, purchase etc. during, say, January 1995; when Master File for sales may contain the same details about year-to-date sales.
Hence the Master Files need to be periodically updated with the data from the relevant transaction files. There are generally a number of Master Files, one for the record of employees, one for fixed assets, and so on.
The name Work File is used to denote a file created during processing operations at some intermediate stage. Sometimes Temporary Files are created to hold some data under processing temporarily. These are automatically deleted when the processing ends. A Scratch File is one which is not needed any more, containing out dated data.
The process of transferring current data of relevant records to build up cumulative total in the respective fields of the master file, or adding /deleting records in the master file based on the current data of the relevant transaction file is called Updating.
In a computer system, it is absolutely essential to keep a duplicate of data files created, preferably at then end of each day. The process of creating such duplicate files is called backing up and the duplicate files are called Backup Files.
In addition, there are a number of standard files, the most important among them being the Program Files, which contain the instructions in a form understandable by the computer, which are required for processing the data to convert them to information.
7. Essay on Data and Information:
Data:
Data is a general term used to denote facts, figures, concepts, logics of true or false, or ideas expressed in a formal manner, using alphabets and or numerical with or without some special symbols, so that it could be processed by a computer. Your name, age, or even good character can all be used as data to derive meaningful information using computers.
However, there is nothing sacrosanct about the terms data and information—one term is often loosely used in place of the other. Moreover, as in industrial production, where the finished product of one process often becomes the raw material of another process, so also one set of information generated by one computer process can be the data for another computer process.
Hence, information is often used to denote the meaning associated with data, the facts or concepts represented by codes. Information is also said to be the data used for decision making.
Let us take the case of processing of examination results by a Board of Education, in general:
1. The primary data is generated at the stage when eligible students fill up the Application Forms giving the relevant information about them.
2. These data is then processed to print out the admit cards, which are information to the individual students. Again, these details from the admit cards are used as data to find out how many students will appear from which centres for which subjects/modules—a new set of information which is used to plan and conduct the examination efficiently.
3. After the evaluated answer-scripts, subject wise, are received from respective examiners in lots, the marks allotted become the data for another process, whose output is the tabulated result of all the students for final decision making by the Board.
Using these processed data, the individual mark-sheets are prepared—an information to the students on their respective performance. The tabulated result is also used to have overall summarised performance for future use. Thus, there is no clear cut demarcation of facts and figures as data or information.
Since the computer processes the data to produce the information, if the data is incorrect the information generated will also be incorrect. Hence, in computer jargon, we have a term called GIGO—Garbage in Garbage Out. It is definitely foolish to blame the computer for incorrect telephone or electric bills, when they entered data are not correct.
Information:
The Output which the computer provides is information and information is the desired piece of knowledge, which is useful to us for various decision making, actions, or reactions.
For example, in a college, the names of all the students recorded using English (or any other natural language) alphabets is a data, the respective roll numbers of a class of students using numerical is a data, the fees paid by each of them is also a data, as far as the college activities are concerned.
Receipt of tuition fees, classified to identify defaulters, summarised to find out the total fees paid during a particular months are the information generated using the students data—a product of data processing. However, both the terms, data and information, are freely used in place of each other.